Recon Rundown #2: GitHub Code Search Preview (for Hackers)

Much to my own surprise, it appears I have kept this New Year's Resolution for more than a single week. I was originally planning on continuing the blog on attack surface that I wrote last week, but this seemed a bit more fun.
The Problem
You might be wondering, why does GitHub need a new way to search the world's code anyway? What's wrong with the old search? There's a long, convoluted answer somewhere explaining how popular text search indexing algorithms work, but I'll offer a simple screenshot to explain my frustration.
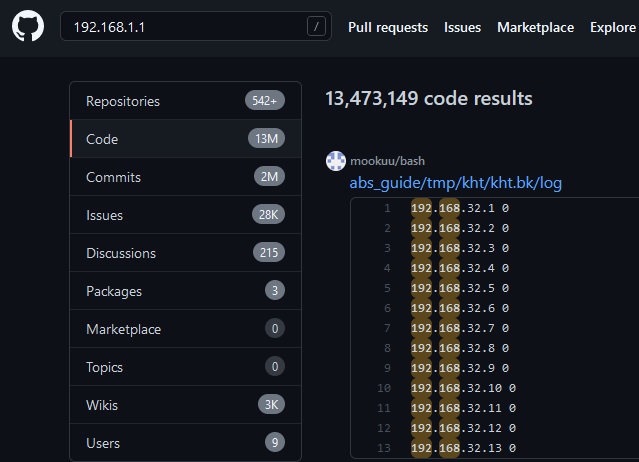
There are many cases where search works well enough for finding subdomains or IPs, which it generally tries to put together in the right order. Often times though you end up having to click through pages of junk to find anything even halfway relevant.
The Solution
There's a LOT of really cool new things which you can read about here, but the two that matter the most are:
- Exact text matches, which we can do by surrounding text in quotes
"LiKe ThIs". This is great for when we know the exact sequence of letters/numbers/special characters that we want. - Regular expressions (regex), which we can do by formatting our query
/[lb]ike this/. Regex is great for when you know about what something is supposed to look like, but don't know what the exact contents are. This specific query will match bothlike thisandbike this, for example.
And these can be mixed with other operators to find a LOT of fun things.
Fun Things Like What?
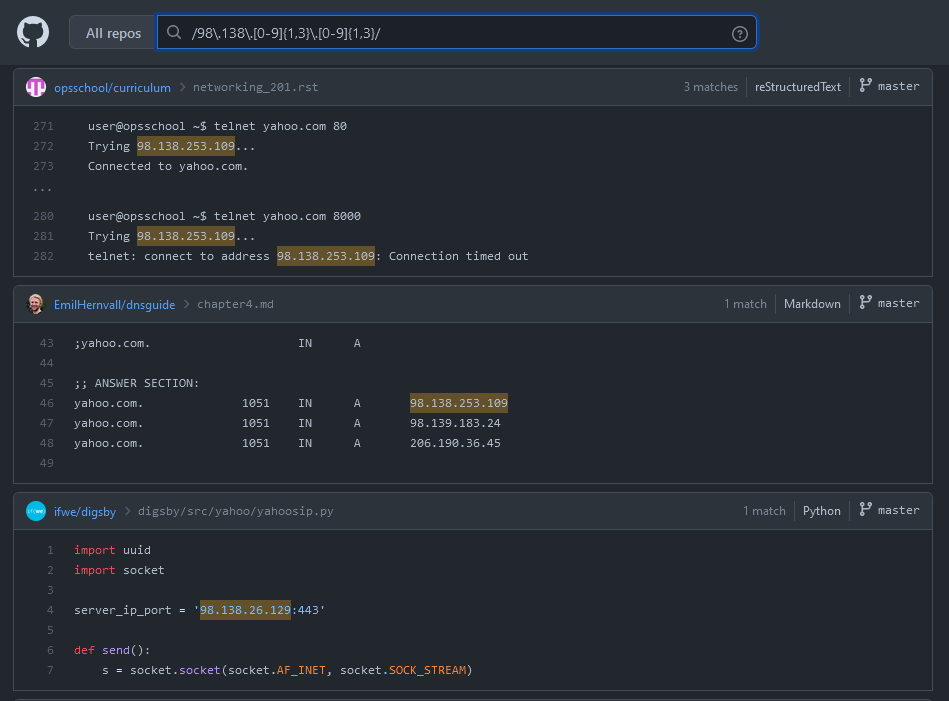
A nice example of something that was previously impossible (and is a nice callback to my last blog) is the ability to find references to IP addresses that belong to specific companies!
We can use the same methods to find these IP ranges on https://bgp.he.net. Oath is of course, the parent company for Yahoo, whose public bug bounty program can be found here

We can use some regex magic to craft a pattern that will match any of the IPs in this range. For those unfamiliar with regex, you can learn it using this handy guide. Regardless, I made a nice nice visual aid below to explain what exactly is going on with this mess of characters.
The results speak for themselves! There are a ton of fun bugs to be found using this exact type of query for those willing to put in the time to dumpster dive through the results.
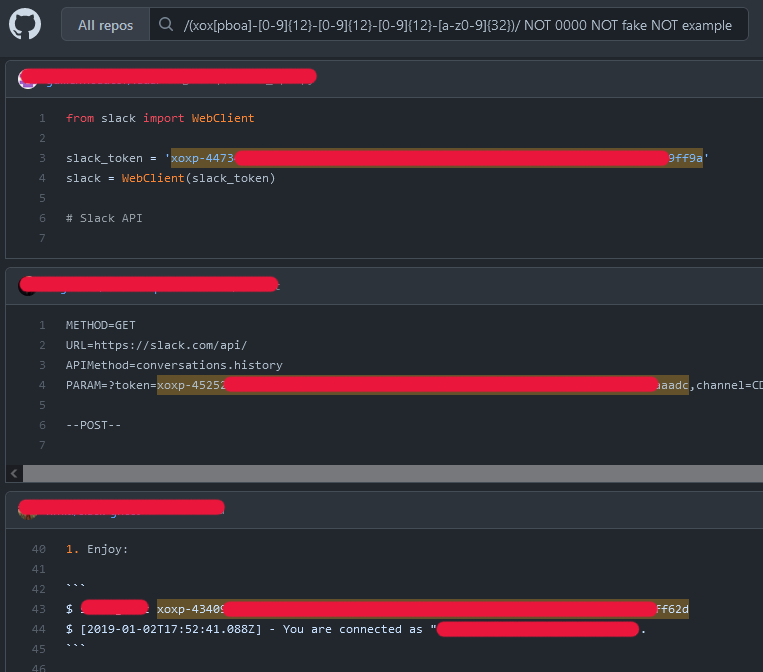
More Examples
There are a TON of different projects on GitHub that help security teams find hard-coded secrets that might have been commited in code, each with their own set of useful regexes we can steal borrow, like this project from Databricks. Also note that we can filter out fake or example data using multiple NOT operator.
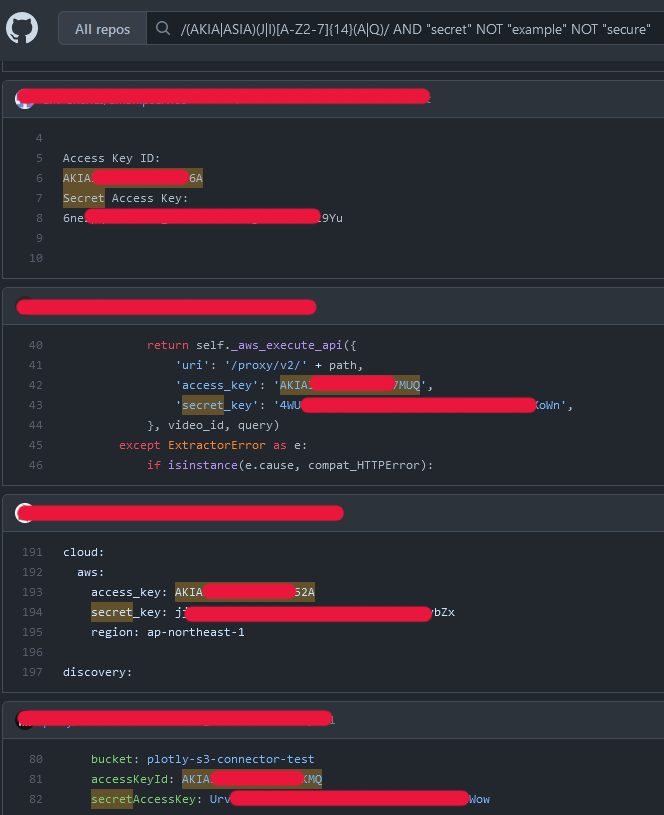
... But what's the catch?
Ah yes, now to the altogether less exciting part of the article. Since this is a feature preview, there are a few quirks that limit it's usefulness (at least for our use-case.)
- There are a maximum of 100 results for each query. You can get around this a number of different ways like
/SECRET_REGEX/ AND "z"to find only secrets that contain the letter "Z." There are much better ways to do this "fake paging," but I'll leave it to the reader to figure that out :^) - Some queries are "too expensive." Some queries are just too complex, requiring too much computing time to be viable for a free product. It's even possible to DoS yourself using a bad regex query, like Cloudflare did that one time.
- Not all repos are indexed. There are plenty of goodies to be found, but a good number of repos aren't searchable yet. This is likely to save lots of processing power and because it's currently in beta. Fingers crossed that everything becomes searchable in the near future!
Finally, if you want to try it out for yourself, you can sign up for the Code Search waitlist now at https://github.com/features/code-search/signup
Links from this Article
- GitHub Code Search Syntax Reference : https://cs.github.com/about/syntax
- Learn Regex the Easy Way : https://github.com/ziishaned/learn-regex
- Cloudflare Outage Post-mortem : https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
- Regexes to Detect Secrets in Code from Databricks : https://github.com/databricks/security-bucket-brigade/blob/master/Tools/s3-secrets-scanner/rules.json
- GitHub Code Search Waitlist Signup : https://github.com/features/code-search/signup
No spam, no sharing to third party. Only you and me.

